Throughput improvements often come from removing avoidable per-transaction overhead, especially in the critical path of a transfer.
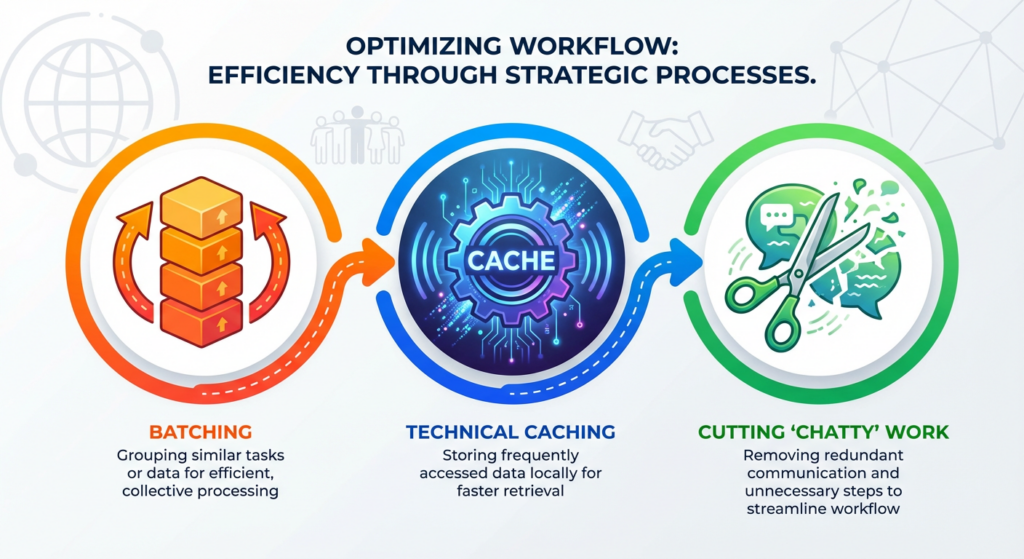
In Mojaloop v17, a large part of the work was exactly that: take the hottest paths in the switch, reduce the number of round-trips and repeated work, and do it without breaking correctness or security assumptions.
The engineering problem: when systems get “chatty”
Payment flows can become “chatty” in a few predictable ways:
- Too many small operations per transfer,
- Repeated lookups that don’t materially change from one request to the next,
- Extra hops in the request path (and extra serialisation/deserialization),
- Hot paths that contain avoidable inefficiencies.
At low TPS, you don’t always notice these costs. At higher sustained load, they become the difference between a stable platform and a platform that is constantly near saturation.
What we changed in Mojaloop v17 (high-level)
The changes focused on reducing critical-path overhead without compromising correctness. The approach combined batching, targeted safe caching, hot-path simplification and evidence-driven optimisation through profiling and disciplined code review.
Across the transfer handlers in Mojaloop v17, the principle was consistent: where sequences of work can be grouped safely, including error paths, eliminate duplicated processing while maintaining strict ledger correctness and integrity.

1) Batching in the transfer handlers
The real-time management of position is the critical function of the Mojaloop switch. This ensures that no unfunded obligations are created between participating financial institutions. This does create contention on the balance of the position account, effectively creating a natural bottleneck. The resulting optimisations substantially reduce the processing overhead of managing the bottleneck, allowing the handler to maintain the high-velocity execution required for accurate position management.
Batching was also applied to the notification handler. Although notifications can be horizontally scaled and are therefore less structurally constrained, batching still improves overall efficiency by reducing repeated work and smoothing throughput under load.
2) Safe caching to reduce repeated lookups
Caching can deliver significant performance gains, but it introduces risk if applied without discipline. The core tradeoff is between latency and correctness: cached data can become stale, potentially returning outdated information and undermining system integrity. For this reason, caching must be introduced selectively, with clear boundaries and explicit ownership of consistency.
In Mojaloop v17, caching was deliberately constrained to scenarios where it delivered a clear benefit with manageable consistency risk:

- High-read, low-change data, such as participant/FSP metadata, where repeated lookups are common but underlying values change infrequently.
- Repeated ID mapping queries that otherwise create unnecessary latency and database load in hot paths.
The goal was not broad acceleration, but the targeted elimination of redundant work while preserving integrity and correctness.
Where necessary, maintaining integrity required architectural adjustments, including relocating certain critical validation checks to more appropriate execution points. This ensures that even when cached data is used for performance, correctness remains enforced at the right layer and cannot be bypassed.
3) Hot-path simplification (removing unnecessary hops)
Sometimes the most impactful optimisation isn’t a new algorithm, but eliminating unnecessary steps in the critical path. In Mojaloop v17, audit messaging highlighted this opportunity. Sidecars had been introduced years ago as a perceived performance optimisation and to support forensic auditing. In practice, however, they became a significant bottleneck, and modern auditing best practices no longer require them. By updating the handlers to (optionally) publish audit messages directly to the Kafka audit topic, we removed the sidecars entirely, reducing hot-path overhead while keeping the audit trail fully explicit and observable.
4) Profiling + disciplined code review
These improvements were driven by two complementary practices:
- Profiling under realistic load to find where time is actually spent.
- Line-by-line review of hot paths to remove obvious inefficiencies early.

What’s next
Part 3 looks at another common limit at scale: bottlenecks in the front-door/ingress path and eventing pipelines, and how removing those caps can unlock the benefits of core-service optimisations.
